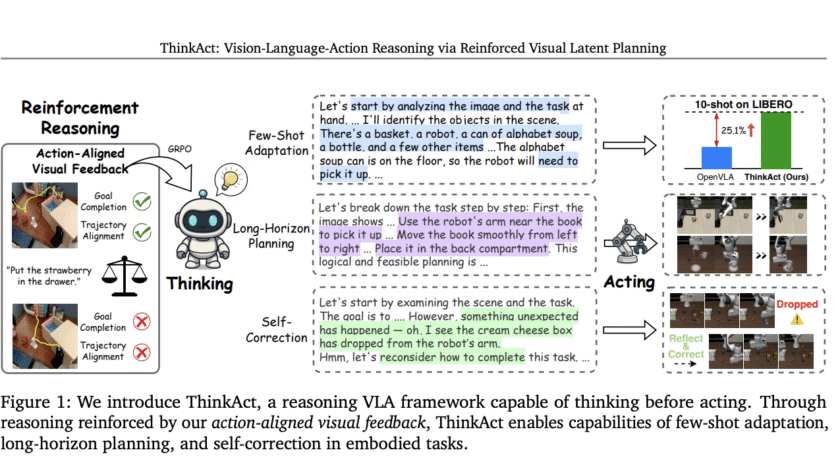
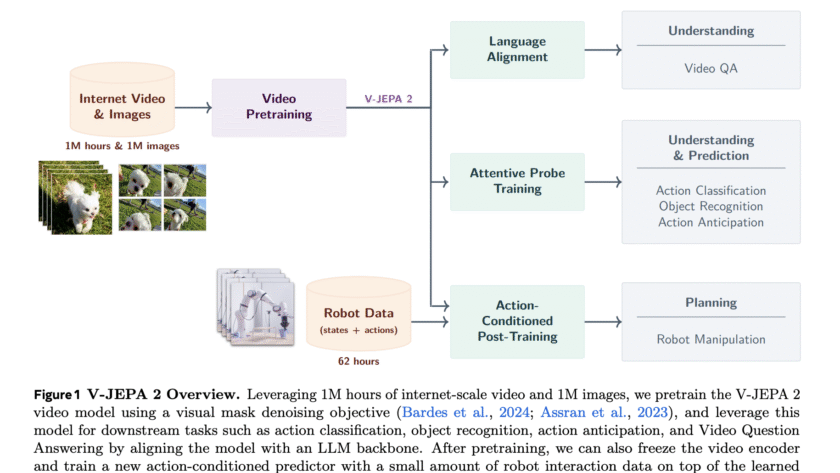
Nvidia made major waves at SIGGRAPH 2025 by unveiling a suite of new Cosmos world models, robust simulation libraries, and cutting-edge infrastructure—all designed to accelerate the next era of physical AI for robotics, autonomous vehicles, and industrial applications. Let’s break down the technological details, what this means for developers, and why it matters to the…