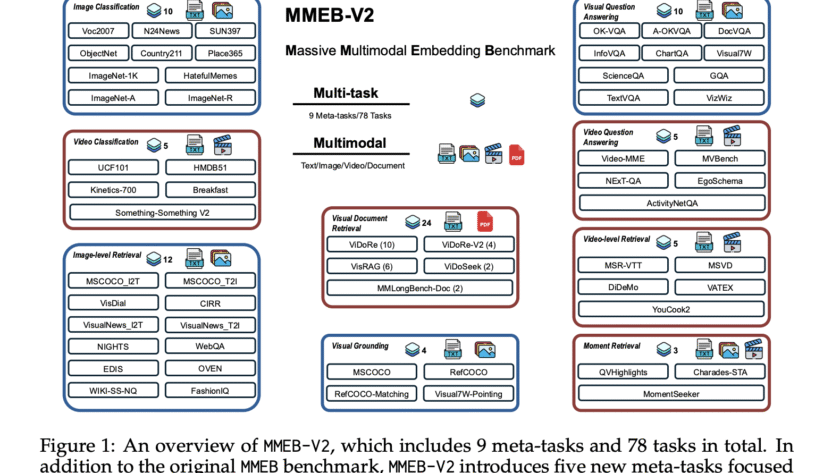
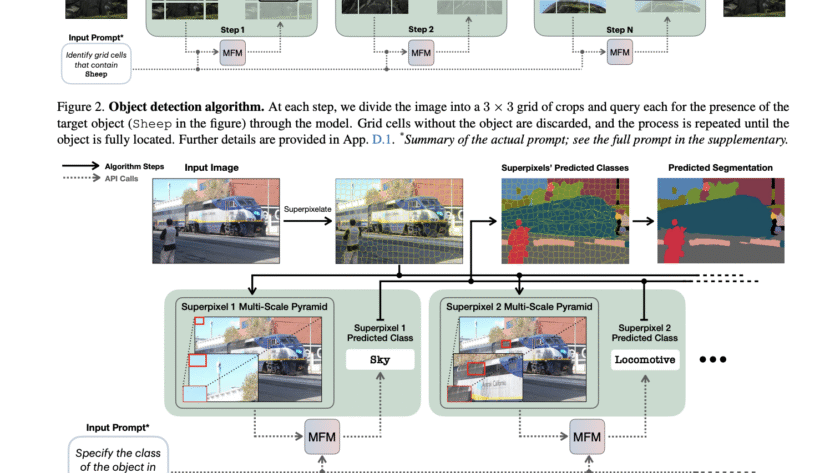
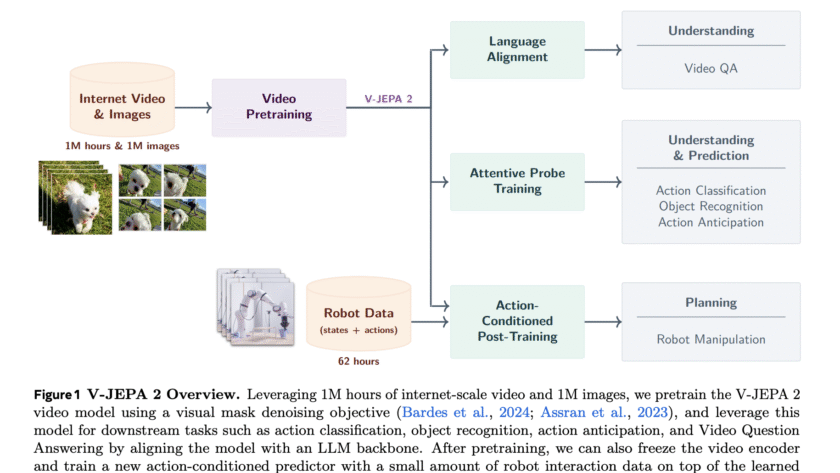
Image by Author | ChatGPT
# Introduction
Over the last couple of years, large language models (LLMs) have become near-ubiquitous protagonists in the AI landscape and across media channels — being sometimes touted as the all-in-one solution to every problem. That might be a slight exaggeration on my part. Still, it's true that…